Chattar
Utilizing computer vision and AR to bridge the gap to language fluency.

role
Product Designer, R&D
tools
Figma, Adobe CC, Replit
year
2025
Links
The Purpose
Language learning began long before apps, textbooks, or formal systems. For most of human history, we learned through immersion. We listened, mimicked, moved through the world alongside others, and picked up meaning through context. Fluency isn’t just taught, but rather lived and shaped through our experiences.
Today’s tools have stripped that process down to streaks and drills. Apps reward you for five minutes of disconnected input just for opening a lesson. We're given phrases to memorize out of context, repeat them to satisfy a metric, and forget them days, if not minutes, later.
To truly learn, we need presence. We need context. We need to feel a connection to what we’re learning in the moment we’re learning it. That means going beyond flashcards and screens, and bringing language into the spaces around us in a way our brain can actually absorb and retain.
"We forget up to 75% of new vocabulary within 48 hours using traditional study methods."
— Cepeda et al., 2006. "Distributed Practice in Verbal Recall Tasks"

The Research
I conducted research independently, from sourcing academic literature to mapping cognitive science against real user needs. My goal was to understand why language learning tools are failing and how people could actually retain and use new languages in real environments.
Foundational Research
I started by reviewing existing learning theories, immersion studies, and retention data from cognitive science, while also auditing leading language apps and analog kits. This helped me understand both the limitations of current tools and the deeper psychological factors that influence fluency.
Users forget up to 75% of new vocabulary within 48 hours when using passive memorization tools.
Cepeda et al., 2006
Immersive AR boosts retention up to 90% after one week, especially when vocabulary is tied to physical space.
EDUCAUSE Review, 2023
Multimodal learning using visual, auditory, and physical cues builds stronger memory networks.
Wu et al., 2013
Real-time corrections help learners speak more comfortably, while situational cues improve comprehension.
Hsu, 2017; Barreira et al., 2012
Synthesis
The findings revealed that fluency is not achieved through repetition alone, but through relevance, context, and engagement. To design a system that could actually help people retain language, I needed to understand what today’s learners truly lack.
Retention is higher when new words are tied to real situations. Learners need to see and hear vocabulary in a meaningful environment to make it stick.
Visual, spatial, and auditory cues work best together. Learners need input that reflects how we actually experience language in the world.
Without timely correction, errors go unnoticed and confidence stays low. A system is needed that supports small, consistent improvement in the moment.
True fluency includes tone, gesture, and social context. Learners need exposure to how language is actually used, not just what the words mean.
The Approach
With the research insights synthesized, I moved into the design and development process. From system mapping to live prototyping, I wanted to test how immersive AR learning could actually function through my proof of concept to be convinced this approach could have impact.
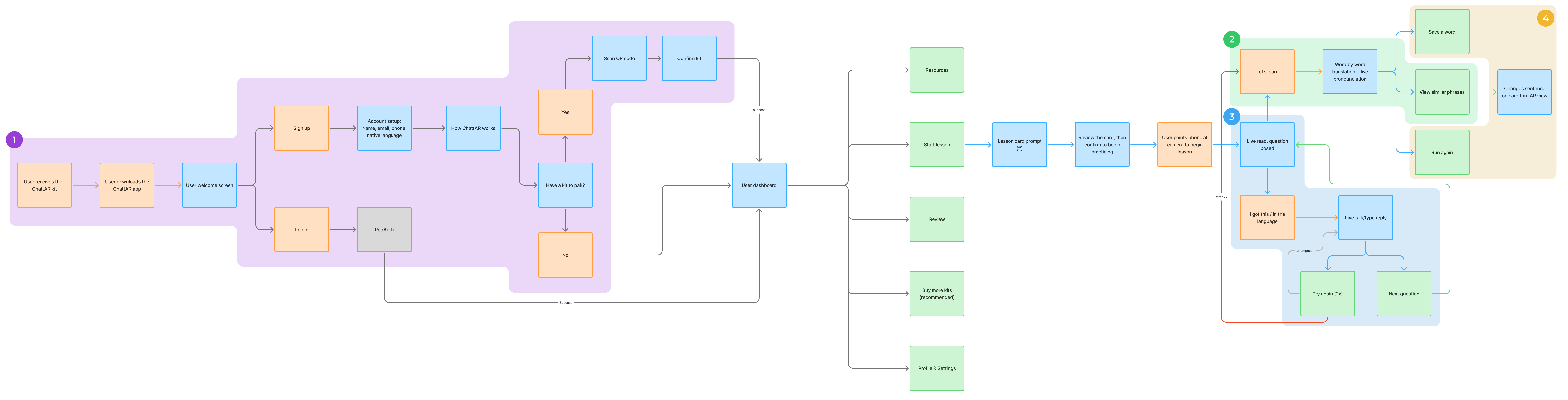
User Flow
This flow was built to reflect how people actually learn through physical interaction, contextual feedback, and progressive input. Each step keeps the user engaged without breaking immersion or forcing unnatural behavior.
Users receive a physical kit. After downloading the app, they are guided to scan a QR code and confirm the kit, entering the system smoothly without extra steps or confusion.
During lessons, users can pause and get immediate clarification. Options include word-by-word translations, pronunciation help, and similar phrase suggestions without exiting the learning environment.
When a user replies to a prompt, the system evaluates their response. If it’s correct, they continue. If not, they are prompted to retry or receive a guided example to reinforce understanding.
Users can save phrases, view variations, or rerun sections at their own pace. These options support deeper learning without relying on forced repetition or gamified pressure.
Wireframing
After finalizing the user flow, I created low-fidelity wireframes to define the structure and core interactions. This stage was used to test layout logic, screen pacing, and visual sequencing before introducing detailed design.
Structured to prioritize comprehension and reduce visual noise, emphasizing the content.
AR elements were introduced gradually to prevent cognitive overload and ensure accessibility.
Design patterns echoed physical kit components to reinforce cohesion across the system.

Primary Designs
Once the interaction model was validated, I created high-fidelity designs to define the final visual and spatial system. These included all core user-facing screens to get an understanding of what the app was for. Core functionalities were also prototyped for showcase.

Development
To test technical feasibility, I developed a working proof of concept using Replit. This phase focused on validating key system behaviors in real-time and usability considerations for the core functions of the immersion experience.
Used to recognize objects and trigger contextual vocabulary prompts. Test for system accuracy.
Modeled spatial language cues to test responses to visual layering while avoiding visual clutter.
Test for the intuitive behaviors and user-expected interactions for immersive learning.

The Results
The technical proof-of-concept validated that real-time object recognition is not only feasible for language learning but uniquely suited to support immersive, context-driven retention. By combining computer vision with live translation logic, the system can actively respond to the learner's environment and reinforce vocabulary through relevance and timing.
Using the COCO-SSD model integrated with TensorFlow.js, I built a live object detection feature capable of identifying 80 common objects in real-time. These include animals, furniture, household objects, and more. Each detected object was automatically matched to a corresponding translation layer, pulled from a localized dataset. If built for real application, an API could be used to expand contextual understanding and datasets to reference.
The system is able to recognize real-world items like “cat,” “bottle,” or “laptop” and provide visual labels through the AR layer.
I created a translation dictionary that linked recognized objects to vocabulary in the target language. This allowed for instant contextual labeling.
The system maintained accuracy and speed across language shifts, confirming capability for multilingual learners in real-time without quality loss.
The user-facing component operates through live camera feed. The system adapts dynamically to prioritize the primary object in frame.
By anchoring vocabulary to the learner’s surroundings and supporting multiple languages in real time, ChattAR shows that immersive learning can be both technically feasible and cognitively effective. This prototype sets the stage for a future where language learning is not reduced to memorization but built through interaction, presence, and meaning.





